

En Estudio34 nos gusta mimar a google, por ello, en todas las auditorias SEO que realizamos tenemos muy en cuenta que todo el contenido quede correctamente etiquetado mediante datos estructurados.
Pero vayamos por partes: ¿Qué entendemos cuando hablamos de datos estructurados?
Los datos estructurados es un etiquetado mediante el cual damos significado al contenido de una web.
Nosotros, como seres humanos, ya lo hacemos por defecto. Somos capaces de dotar de significado a las diferentes palabras. Sabemos que este contenido se trata de un entrada en un blog, que “Datos estructurados: cómo añadir schemas usando google tag manager” es el título, “Merche” es la autora, el primer párrafo comienza con “En Estudio34 nos gusta mimar a google” y que el post tendrá 5 estrellas 😉
Pero para los diferentes buscadores, las palabras son palabras, y las estrellas, símbolos raros. Por lo tanto, hace falta que alguien le diga a Google qué es cada cosa (al menos de momento).
Con esto, te estarás preguntando… ¿podemos utilizar cualquier “atributo” para etiquetar el contenido? Por supuesto, puedes utilizar lo que quieras, pero no te va a entender ni bing…
Así que aquí es donde entra en juego schema.org: una especie de “wikirobots” que recoge de forma muy simple las etiquetas que debemos utilizar para el marcado semántico (y que todos los robots entienden, ¡hasta bing!).
Pero, ¿qué implicación tiene los datos estructurados en los resultados de búsqueda?
¡¡Rich Snippets!!

También featured snippets. ¡Sí, featured snippets! Ya que no nos engañemos… aunque los schemas no es una condición sine qua non para los featured snippets, ya que interfieren muchos otros factores, es más fácil que google interprete correctamente el contenido si las páginas están correctamente etiquetadas.

No me enrollo más y os explico cómo etiquetar el contenido:
Cómo implementar los datos estructurados
Existen 2 métodos para implementar los datos estructurados:
1. Microdatos y RDFa
2. JSON-LD.
El método 1 consiste en intercalar los atributos en el contenido. El método 2 consiste en añadir un bloque de código con todos los atributos.
Entonces queda claro que utilizaremos el método 2 para implementarlo con Google Tag Manager.
En este caso, os voy a enseñar un caso muy reciente, donde decidimos etiquetar las preguntas y respuestas de diferentes páginas de tratamientos de una web corporativa de cirugía estética.

Paso 1: Crear variables
El objetivo es simplificar el proceso de etiquetado, por lo tanto, no tendría mucho sentido implementar schemas sin utilizar variables.
El objetivo con las variables es recoger los elementos que queremos etiquetar. En nuestro caso, las preguntas y las respuestas.
Para crear variables en GTM, primero de todo, debemos crear una nueva variable y hacer clic en DOM ELEMENT.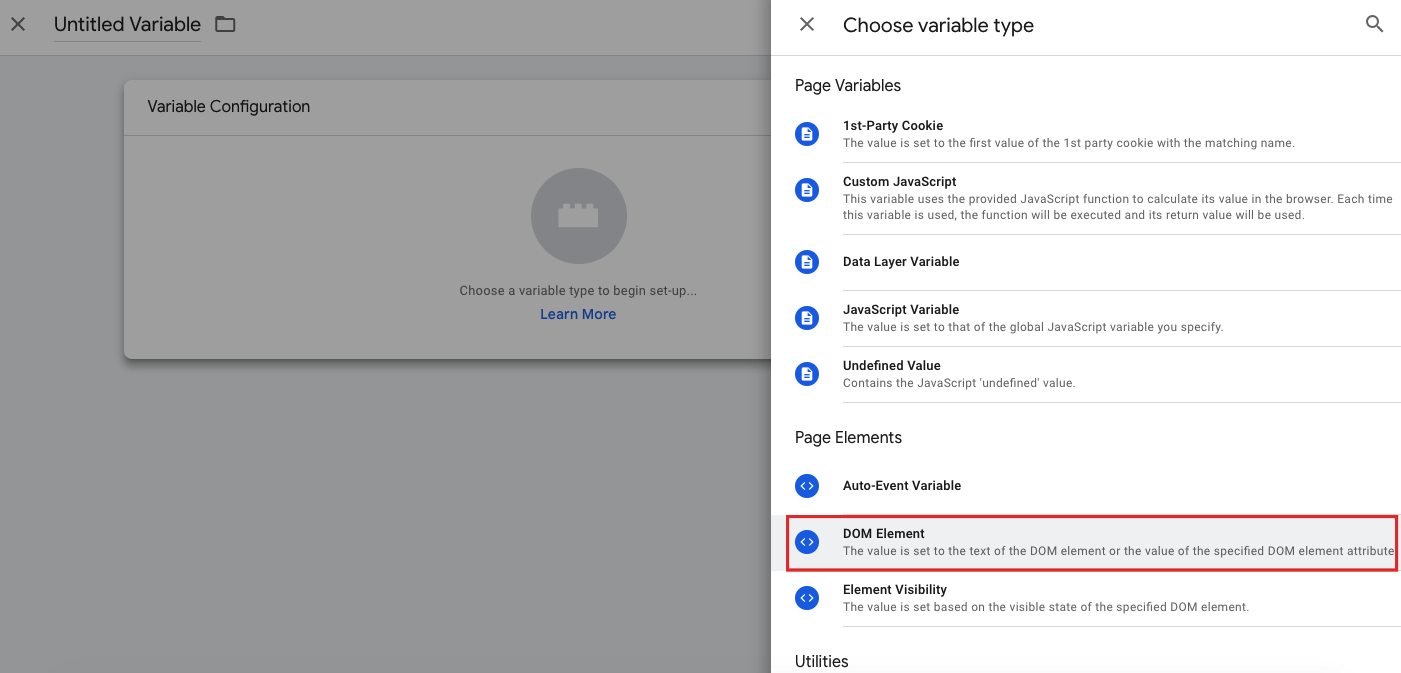
Y detectar qué selector CSS podemos utilizar. Esto dependerá mucho del html de vuestra página, en nuestro caso utilizamos:
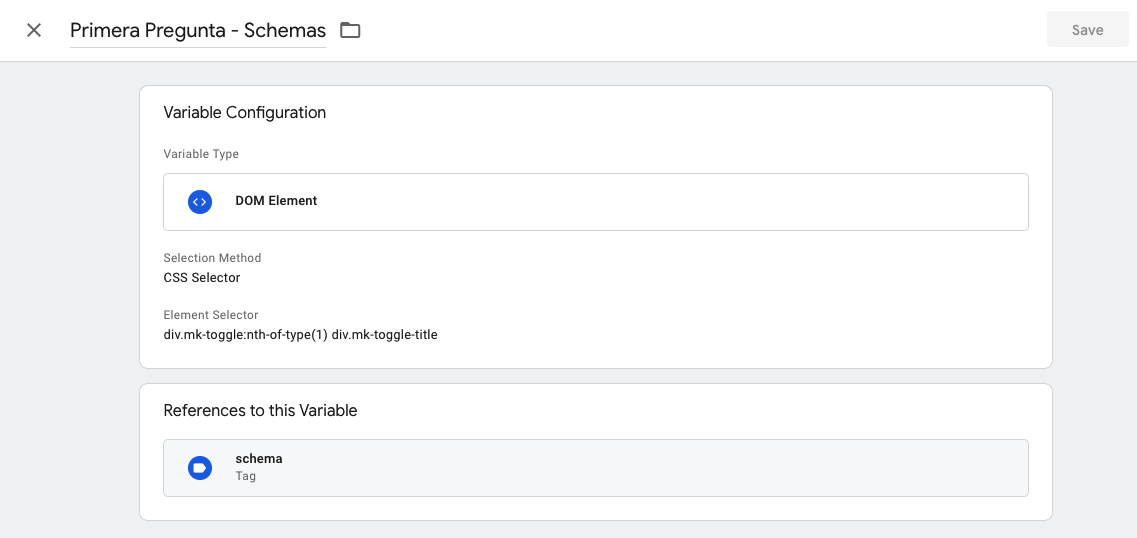
div.mk-toggle:nth-of-type(1) div.mk-toggle-title para la primera pregunta

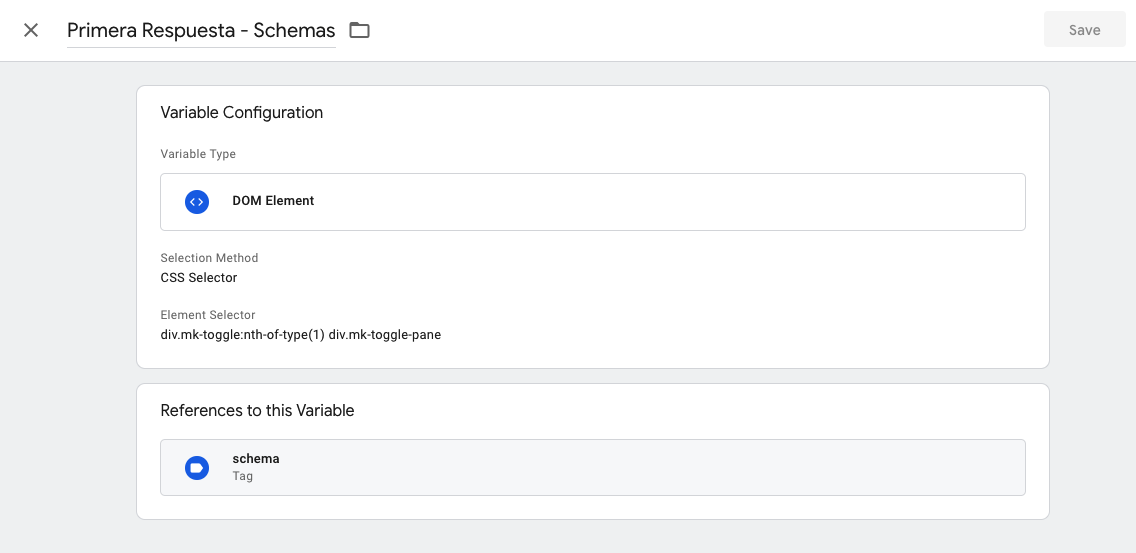
div.mk-toggle:nth-of-type(1) div.mk-toggle-pane para la primera respuesta

Y fuimos modificando el nth-of-type(X) para las preguntas siguientes (ya que todas seguían el mismo etiquetado).
Una vez tuvimos las variables creadas, chequeamos si se recogían correctamente en el preview:
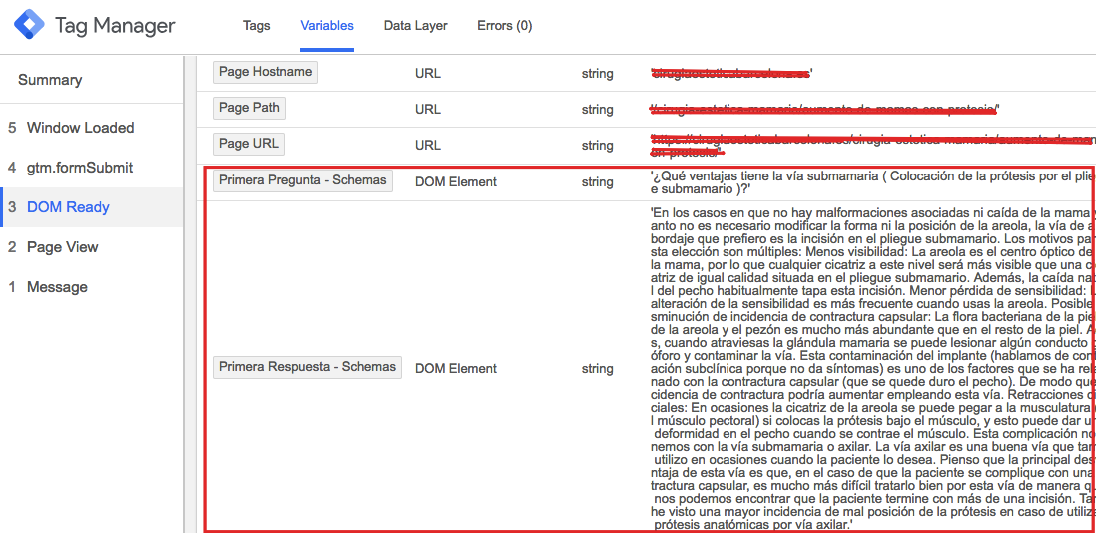

En todo caso, si aún no os atrevéis con las variables, podéis saltaros este paso.
Paso 2: Crear un tag custom HTML y añadir el JSON-LD
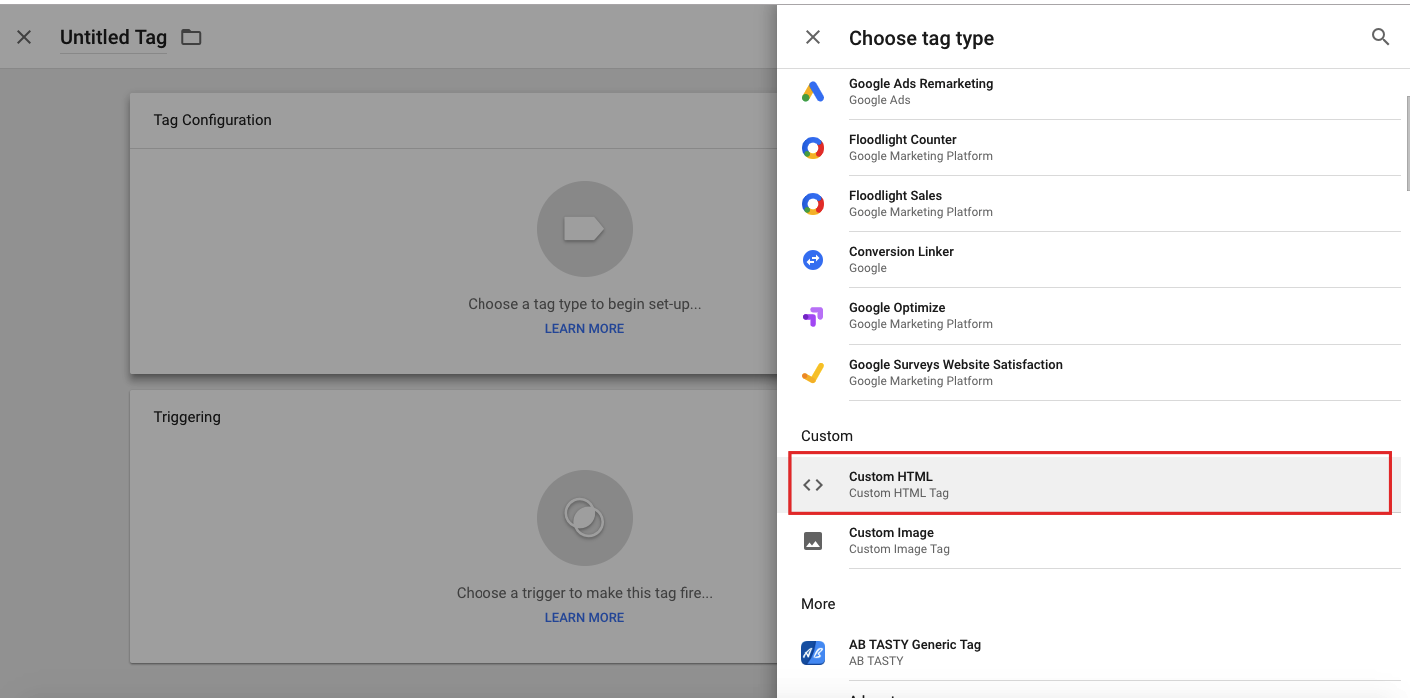
Para crear el JSON podéis utilizar programas como:
https://hallanalysis.com/json-ld-generator/
o la propia herramienta que facilita google:
https://www.google.com/webmasters/markup-helper/u/0/
En nuestro caso, utilizamos el siguiente script ya que el objetivo era etiquetar las diferentes preguntas y respuestas:

De todas formas, os recomiendo que modifiquéis un poquito el código, ya que hay problemas con la herramienta de prueba de datos estructurados de Google, y no interpreta bien los fragmentos JSON-LD de la etiqueta HTML personalizada de Google TagManager.
Para solucionar esto basta con agregar los siguientes cambios:

Como veis, nosotros hemos utilizamo las variables {{Primera Pregunta – Schemas}}, {{Primera Respuesta – Schemas}},{{Segunda Pregunta – Schemas}},{{Segunda respuesta – Schemas}}.
Aunque también lo podéis hacer manual, y en lugar de utilizar variables, podéis pegar el texto directamente. Aunque, en este caso, deberéis hacer un tag de todas y cada una de las páginas que queréis etiquetar.
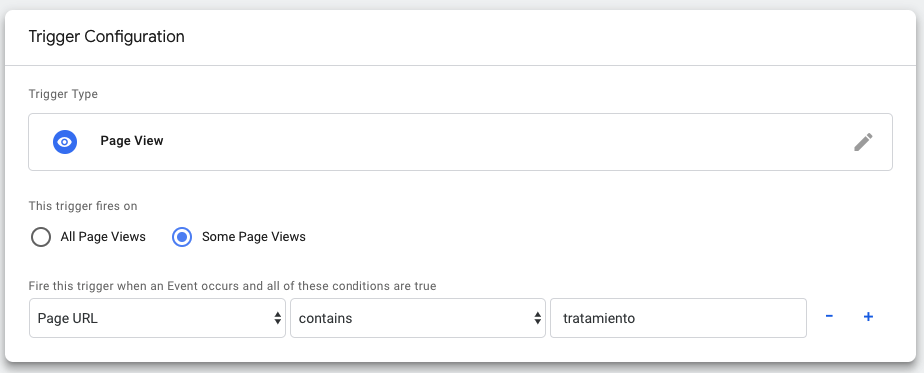
Paso 3: Definir el trigger
El trigger, como en las variables, dependerá mucho de la estructura de vuestra página web. En nuestro caso, todos las páginas que contienen este tipo de preguntas/respuestas cuelgan de una url que contiene “tratamientos” en la URL.
Por lo tanto, el trigger fue así:
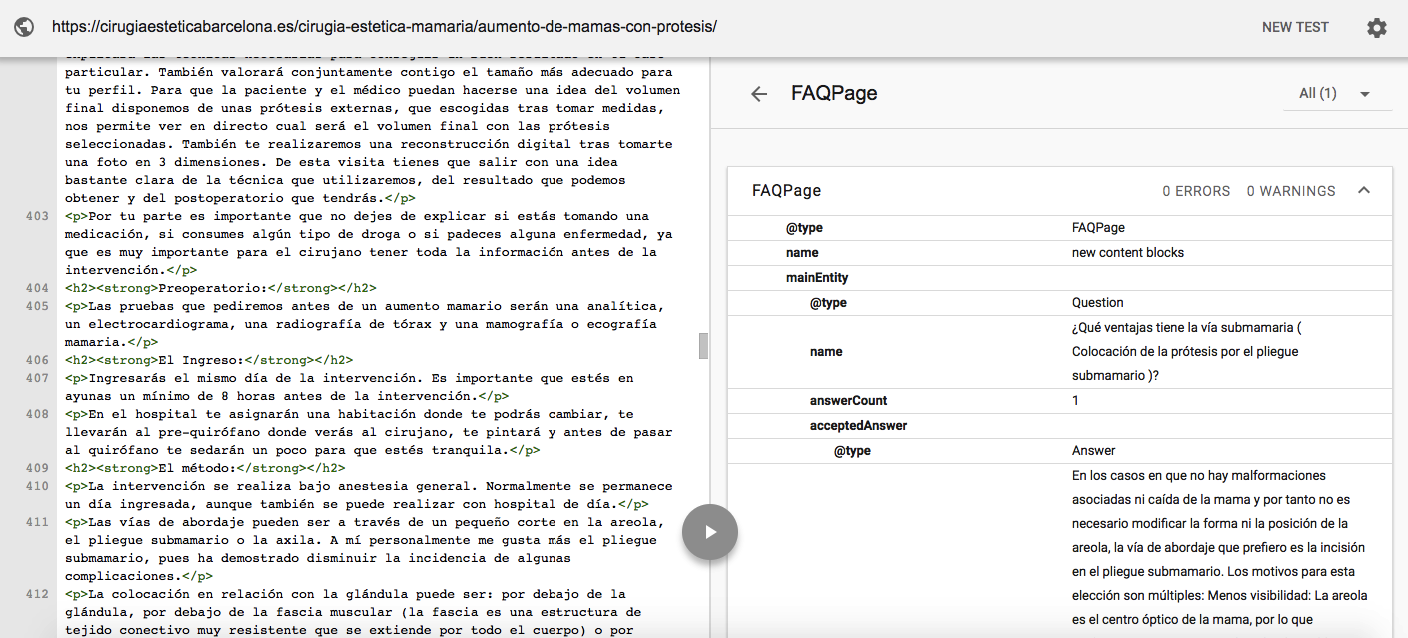
Con esto, solo quedaría publicar y checkear que nuestro etiquetado sea correcto. Para ello podemos ir directamente a https://search.google.com/structured-data/testing-tool y testear.
¡Ya no tienes excusa! Anímate y mima a google con datos estructurados.


