

Los problemas de tener URLs duplicadas

Recientemente nos hemos encontrado un caso curioso de caída de tráfico que nos gustaría compartir. Un cliente nos comentó que estaba viendo cambios extraños en su volumen de tráfico, por lo que hicimos un análisis de lo que estaba pasando. Si bien vimos relación con las frecuentes actualizaciones del algoritmo de Google que ha habido durante 2021, nos encontramos con un factor más: URLs duplicadas.
Por qué las URLs duplicadas son un problema
Cuando hablamos de URLs duplicadas nos referimos a que existen varias versiones de la página dentro de una misma web: es decir, 2 o más páginas con nombre idéntico, mismos textos, mismas imágenes, mismos enlaces… Lo solemos encontrar de varias formas, pero las más comunes son tenerla en HTTP y HTTPS (http://example.com y https://example.com), con www y sin (https://www.example.com y https://example.com ), y con / al final y sin (https://example.com/ y https://example.com). Esto sucede cuando hemos creado la web con un protocolo, y en algún momento hemos hecho un cambio sin eliminar la versión anterior, de manera que siguen existiendo ambas.
También puede pasar que nuestro gestor de contenidos esté generando parámetros de forma automática, con lo que nos quedaría algo de este estilo https://example.com/product1/ y https://example.com/product1?color=blanco
Más allá de que pueda parecer un despiste al subir el contenido, ¿qué problema supone? Pues varios:
En primer lugar, tenemos el crawl budget. Podríamos decir que Google asigna una cantidad de tiempo para rastrear cada página de todo Internet, y así saber si están caídas, tienen cambios, etc. La cantidad de tiempo que le va a dedicar a tu web depende de varios factores, pero siempre va a ser una cantidad limitada, a la que llamamos “crawl budget” (presupuesto de rastreo). Por lo tanto, si resulta que a nuestra web le toca solo una atención limitada, lo mejor es que vaya a las URLs que más nos importan. Pero cuando las tenemos repetidas, corremos el riesgo de que parte de ese budget se dedique en rastrear las copias de las URLs que ya había rastreado, con lo que lo estamos gastando en algo que no nos aporta nada, a costa de que no llegue a las que sí que queremos que lea.
Además, si tenemos una gran cantidad de contenido duplicado en nuestra web, corremos el riesgo de sufrir una penalización de Google. En realidad, esta es una penalización muy útil para los usuarios, ya que generar contenido de calidad lleva mucho tiempo, y sin ella, sería muy fácil llenar las webs con cualquier texto copiado varias veces que no nos aportaría nada.
Por último, si Google lee las dos páginas y ve que son exactamente iguales, lo más probable es que decida mostrar sólo una de las dos, que tal vez no coincida con la que tú prefieres. A veces sucede que durante un tiempo muestra una y luego la otra. Te harás a la idea de que analizar tu tráfico en estas circunstancias va a ser un caos.
Análisis del tráfico
En el caso de nuestro cliente, detectamos que tenía las mismas publicaciones de su blog en dos versiones: www.example.com/Blog y www.example.com/blog, ambas con las publicaciones indexadas y estatus 200.
Para analizarlo en detalle, vimos el comportamiento de cada versión por separado:
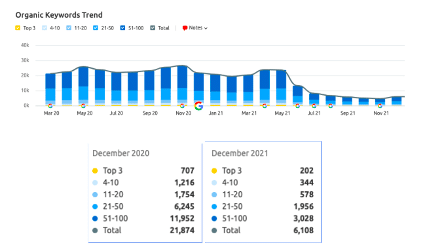
Las URLs de la versión /Blog habían tenido mucha visibilidad hasta mayo de 2021, cuando esta empieza a descender y en el momento de la investigación se mantenía en valores bajos.
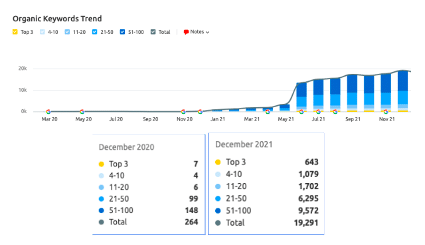
En cambio, las URLs de la versión /blog justo en esas fechas empiezan a tener visibilidad, aumentando la cantidad de keywords posicionadas en top100.
Vemos un claro solapamiento entre las dos versiones del blog, entre las que se está produciendo una canibalización de palabras clave y URLs. A nivel de estrategia, es necesario conseguir que solamente una de las dos versiones tenga visibilidad.
¿Cómo solucionar las URLs duplicadas?
Una vez las hemos detectado y sabemos que nos están perjudicando a nivel de tráfico y posicionamiento, ¿qué podemos hacer?
Nuestro consejo es, en primer lugar, revisar el tráfico de las distintas versiones, para decidir con cuál de ellas nos interesa quedarnos. Además, una web siempre debería tener el mismo formato en todas sus URLs, por lo que deberíamos plantearnos cuál queremos que sea y ser consistentes.
Una vez decidida la versión, se trataría de desindexarlas para que no fueran rastreables, y redirigirlas hacia la versión que sí usaremos. De esta manera, nos quedaremos con el valor SEO que tenían las URLs desindexadas.
En el caso de las URLs con parámetros automáticos, habría que investigar en la configuración de nuestro gestor de contenidos por qué se están produciendo y corregirlo. Otra opción sería aplicar una etiqueta rel=canonical hacia la versión sin parámetros de esa página, ya que de esta forma le estamos diciendo a Google que sólo rastree esa.
Por último, deberemos revisar el sitemap de nuestra web, eliminar de él las URLs que han sido desindexadas y asegurarnos de que contiene las URLs que forman nuestra web actualmente.
Como hemos visto, tener URLs duplicadas en una web puede dar serios problemas de tráfico y posicionamiento, por lo que conviene solucionarlos cuanto antes. Es bueno hacer revisiones periódicas de nuestra web para asegurarnos de que todo está en orden, y en caso de duda, no dudes en llamarnos. ¡Estaremos encantados de ayudarte!


